


There's a technique that's become central to how serious teams evaluate AI output. It's called LLM-as-judge: using a separate language model to score the quality of your application's responses. And it's genuinely useful, with roughly 80% agreement with human evaluators at somewhere between 500 and 5,000 times the cost-efficiency of human review. For teams trying to evaluate tone, helpfulness, or safety at any kind of scale, it's probably the most practical option available.
Here's what doesn't get talked about enough. Most teams deploying LLM-as-judge are doing it wrong, and the scores they're getting back are telling them a story that isn't true.
I'm not saying this to be provocative. I've seen it happen. Teams run their evaluation suite, see high pass rates, ship with confidence, then watch quality degrade in production with no corresponding signal in their test results. The judge kept saying things were fine. The users eventually said otherwise.
Before getting into the specific failure modes, there's a mental-model issue worth addressing.
When you deploy an LLM-as-judge, you aren't installing a neutral measurement instrument. You're deploying another LLM, with all the same properties that make LLMs interesting and unreliable. It has biases, it responds to surface features that shouldn't matter, it can be gamed, and it has blind spots.
So treat the judge as software that can have bugs. It needs to be tested. It needs to be calibrated against ground truth. And it needs to be maintained when the underlying model it runs on gets updated.
Most teams don't do any of that. They pick a judge model, write a rubric, plug it into CI, and trust the scores. That's how you end up with metrics that look good and quality that doesn't.
This one is probably the most widely known and the most widely ignored.
LLM judges systematically favor outputs from their own model family. If your application runs on GPT-4 and your judge is also GPT-4, the judge will rate GPT-4 outputs more favorably than it would rate identical outputs from Claude or Gemini. Not because the outputs are better, but because they feel familiar.
The fix is simple. Don't use the same model family for both the application and the judge. If you run GPT, use Claude or Gemini as the judge, or the other way around. What matters is the separation.
I still see teams skip this, usually for convenience. They already have an OpenAI API key, so it's easier to just use the same model. That convenience is costing them evaluation accuracy they don't know they're missing.
LLM judges inflate scores for longer responses by roughly 15%. That might sound minor. It isn't, for two reasons.
First, 15% on a 1-10 scale is a full point and a half of systematic error, which is enough to flip pass/fail decisions. Second, and more insidious: if your product needs concise outputs, your evaluation is actively working against the quality goal. You're deploying a judge that rewards the exact thing you're trying to discourage.
The fix is two-part. Use a 1-4 scale instead of 1-10, because judges are more reliable at coarse-grained distinctions. And explicitly reward conciseness in the rubric. If conciseness matters for your feature, put it in the criteria. "Penalize unnecessary length" is a legitimate instruction to give a judge.
This is the one I think matters most in practice, even though it gets the least attention.
Before you trust a judge in your CI pipeline, validate it against human-labeled examples. Take 50 to 100 cases, the kind of input-output pairs your feature actually handles, have human raters score them against your rubric, then run the judge against the same cases and compare. You want roughly 80% agreement within plus or minus one point.
Most teams don't do this. They write a rubric, test it on a few examples by hand, decide it "looks right," and ship it.
Then the judge passes things it shouldn't. The automated test suite shows green. Real users hit quality problems that never appear in the metrics. Someone eventually notices the judge isn't actually agreeing with human judgment on the things that matter, and by then trust in the eval infrastructure has eroded.
The calibration step takes maybe a day of work the first time. It is not optional if you want your evaluation to mean anything.
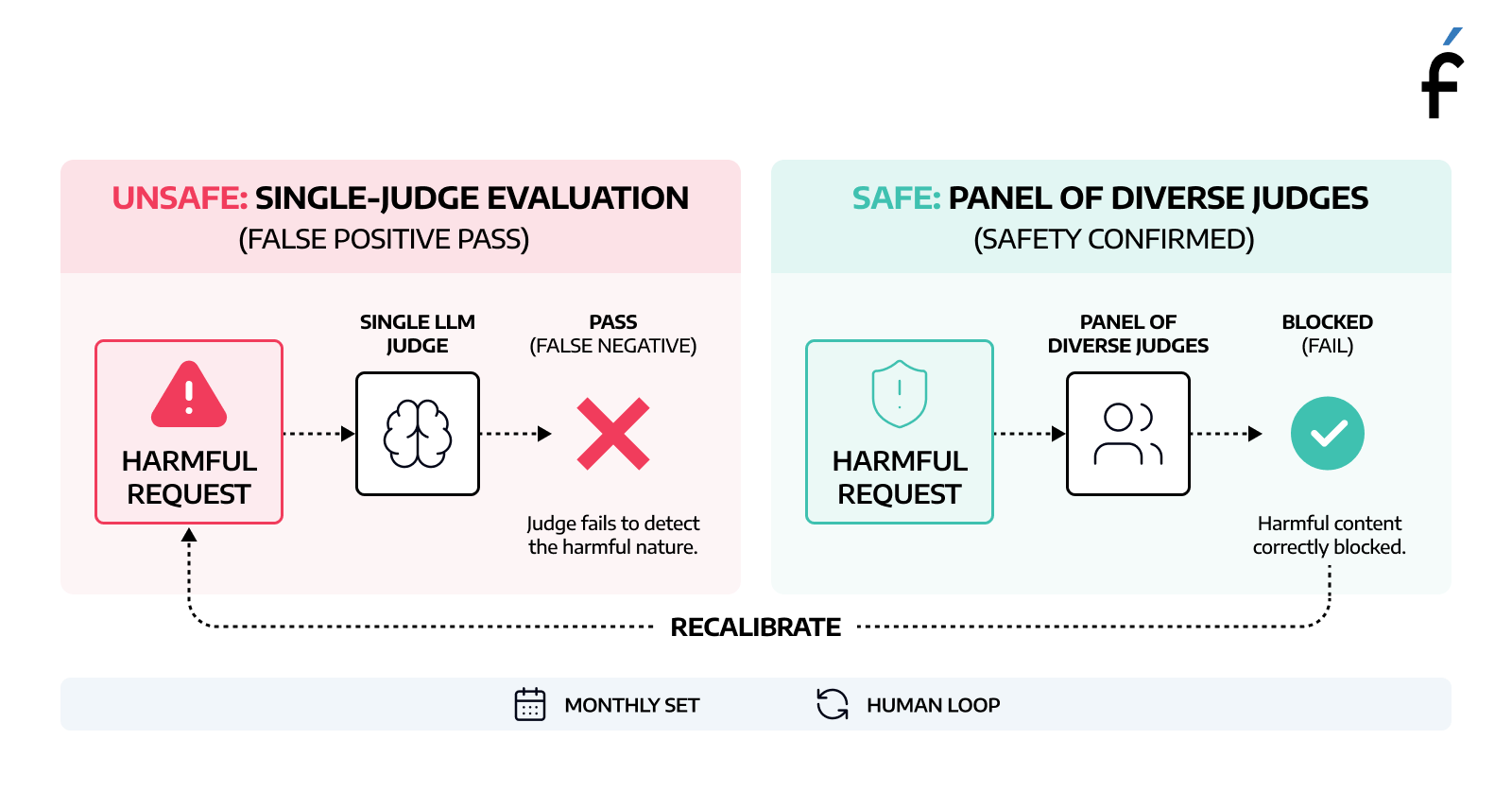
Single LLM judges perform at about a 50/50 clip on adversarial safety inputs.
This is well documented in the research. When you're testing whether your AI refuses harmful requests, maintains appropriate guardrails, or resists prompt injection, a single judge evaluating that is not reliable. You need a panel: three judges from different model families, with majority agreement required to pass.
For most quality dimensions, a single well-calibrated judge is adequate. For safety-critical evaluation, it isn't. These are different situations and shouldn't be treated the same way.
None of this means LLM-as-judge is the wrong tool. It means it's a tool that has to be used correctly. The setup that actually works:
One more thing belongs on that list: log the judge's reasoning, not just its score. When the judge fails a test case, the reasoning tells you why. Without it, you have a number and no way to diagnose what's actually wrong.






Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



