


There's a pattern I keep seeing, and it's worth looking into.
A team does the work. They build an eval set, write a judge rubric, and get 80-something percent agreement with human raters. They ship the feature with reasonable confidence. Six weeks later, the support tickets start to change in character. The chatbot is giving different answers than it used to. Someone notices the tone has shifted. A manager asks what happened to quality, and the honest answer is that nobody knows, because nobody was watching.
The quality didn't collapse. It drifted. And drift doesn't show up in a test suite that only runs before deployment.
Traditional software doesn't generally get worse over time without a code change you can point to. AI features do, for reasons that have nothing to do with your code.
The first is model updates. LLM providers update their models, and sometimes they announce it, but more often the same model name just starts behaving differently. The model you tested against in March may not be the one running in May. If you're not version-pinned, and many teams aren't because the API defaults to current, you're running a model that was never tested.
The second is retrieval drift. If your feature uses RAG, where the LLM answers based on documents pulled from a knowledge base, that knowledge base changes. Documents get added, updated, or removed, and the retrieval system starts pulling different context than it used to. The LLM generates different answers, not because the model changed, but because what you fed it changed.
The third is shifting usage patterns. Real users ask questions the test set never anticipated. As the user population grows or the product evolves, the distribution of inputs drifts away from what you evaluated against, and edge cases become common cases.
None of these trigger an alert. None of them show up in your CI pipeline. The test suite stays green because it's still running against the inputs and expectations from launch day.
Pre-production evaluation tells you whether a feature is ready to ship. It doesn't tell you whether it's still working.
This is the gap most teams don't address until something visibly goes wrong, and the visibility usually comes from the wrong place: user complaints, a bad support ticket, someone in leadership noticing that outputs seem off. By the time you have that signal, you've already delivered degraded quality to users for weeks.
What you want instead is a signal that fires before users notice. That requires actually scoring production outputs, not just pre-deployment ones.
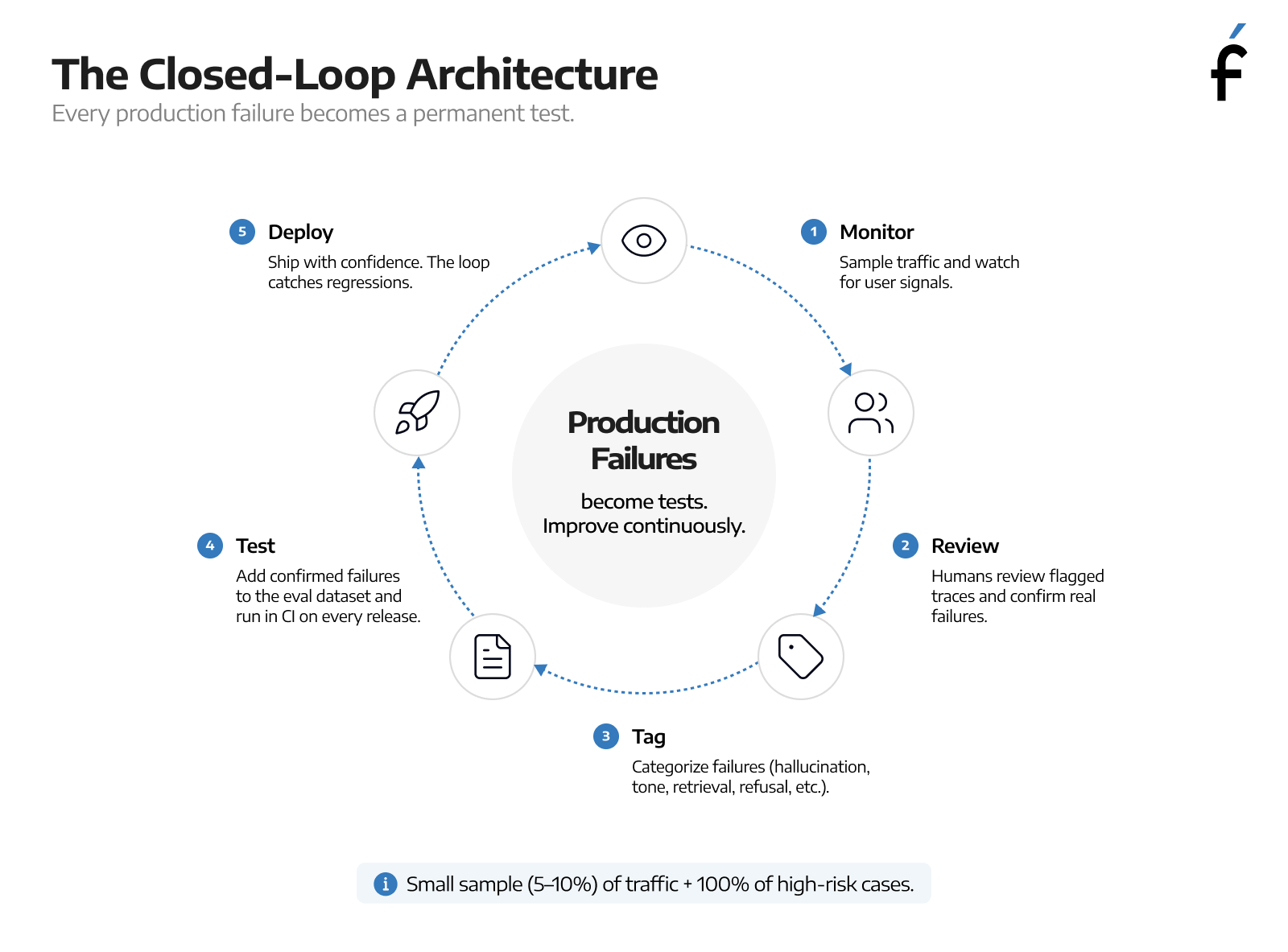
The pattern that works is straightforward to describe, though it takes some infrastructure to build.
Sample production traffic continuously. Not all of it, which would be prohibitively expensive, but typically 5 to 10% of total traffic plus 100% of high-risk categories, meaning anything involving financial decisions, medical information, or other sensitive outputs. Run those samples through the same evaluation infrastructure you use in CI: schema checks, semantic similarity, LLM judge, hallucination scorer. When scores drop below threshold, flag the trace for human review.
In parallel, watch for implicit user signals: conversations that end abruptly, users rephrasing the same question several times, escalations to a human agent. These are free to capture, and they catch failures that users notice strongly enough to signal.
Human review confirms whether flagged traces are real failures or false positives, and categorizes the real ones. The tagging matters here. Is this a hallucination, a tone problem, a retrieval failure, a refusal that should have been an answer? Confirmed failures go into your eval dataset and become permanent regression test cases.
That's how the loop closes. Production failures become tests, CI runs those tests on every release, and you can't ship a regression without seeing it in the build.
Traditional QA closes a similar loop, since production bugs eventually become regression tests. What's different here is the operational mechanics.
In traditional QA, the loop is manual and slow. A bug gets filed, it gets triaged, someone writes a regression test, and it gets added to the suite. That cycle might take weeks.
In AI QA, if you build the infrastructure right, the loop is automatic. A trace gets flagged, a human reviews it in an observability platform, confirms the failure, tags it, and it propagates into the eval set. The whole thing can happen in hours rather than weeks. The test suite then grows at a pace that reflects actual production failure modes, not just the ones your team anticipated before launch.
The teams that have this running aren't simply doing better pre-launch testing. They have a fundamentally different quality cadence. They see problems before users do, and their eval dataset is a living thing that gets smarter over time.
If you don't have production monitoring for your AI features at all, start with observability. You need to be capturing traces before you can do anything else. Langfuse is open-source and self-hostable, Braintrust is strong on the eval-experiment workflow, and Arize Phoenix covers both traditional ML and LLM observability if you have a mixed portfolio. Pick one and start logging.
Once traces are flowing, set up automated scoring against your samples, even if it's just schema validation and a basic hallucination check to start. You want a signal before you have an incident. The full architecture, including sampling strategy, the two-track flagging approach, and how to build the human review workflow, is covered in the AI Testing Playbook at [fortegrp.com/ai-testing-playbook].
Pre-production evaluation is table stakes. What separates teams that maintain quality from teams that chase it is whether they've closed the loop between production and the test suite.






Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



