


I've spent over 30 years in software quality. I've watched the industry wrestle with client-server, then web, then mobile, and each time the core testing practices had to adapt, sometimes slowly and sometimes painfully. We're in another one of those moments, and I'm not sure most teams realize it yet.
If your organization is shipping AI-enabled features (a support chatbot, a document summarizer, a RAG-based assistant) and your QA approach is still built around pass/fail assertions against expected outputs, you have a problem. Not a theoretical one. It's biting teams right now.
Traditional testing is built on determinism: same input, same output, every time. That's the foundation under every unit test, every integration test, and every regression suite your team has ever written. LLMs don't work that way.
The same prompt, sent to the same model, can produce different outputs across runs. The phrasing changes, the structure changes, and sometimes the content changes in ways that actually matter. This isn't a bug you can file. It's how these systems work.
The instinct I see most often is to reach for temperature=0: lock it down, make it deterministic, test it like normal software. That doesn't fix it. Recent research has shown that even at temperature=0, running the same prompt a thousand times can produce dozens of different completions, because floating-point arithmetic behaves differently across GPU batches and providers push model updates without telling you. The non-determinism is baked in at a level you can't configure away.
So your choices come down to two. Keep writing tests designed for a different kind of system, or start building a test approach that fits what you're actually shipping.
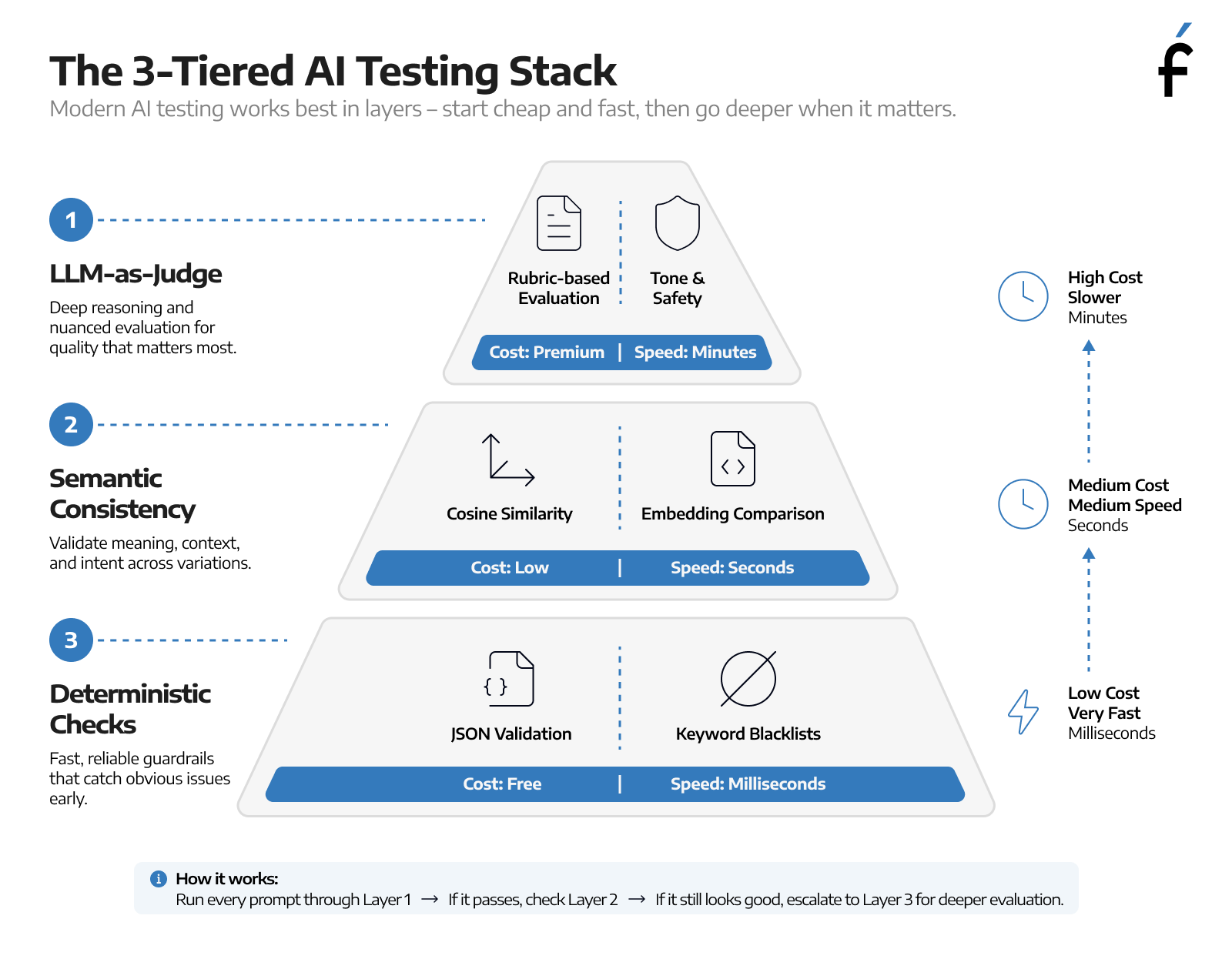
The shift I'd encourage is from "does this output match what I expected" to "does this output have the properties that matter." It's a different question, and answering it takes a layered approach.
Start with what's still deterministic. Not every property of an LLM output is probabilistic. Is the response valid JSON? Are the required fields present? Does the output avoid terms it was instructed to avoid? These checks are free, they run in milliseconds, and in my experience they catch more failures than people expect before the expensive evaluation layers even run. Run them on every commit.
Add semantic consistency checks. If your application is supposed to answer "how do I return this item?" and "I'd like to send this back, what's the process?" the same way, you can test for exactly that. Embed both responses and measure cosine similarity. You're not checking exact text, you're checking whether the meaning held, which is far more useful than an assertion that fails every third run because the word "here" moved.
Use an LLM to evaluate your LLM. This sounds circular but it works. A separate model, given a structured rubric, can evaluate qualities like tone, helpfulness, and safety at a fraction of the cost of human review: roughly 500 to 5,000 times cheaper, with about 80% agreement with human evaluators on most tasks. We call it LLM-as-judge, and it's become central to how I think about AI testing.
A few things I've learned the hard way about getting it right. Never use the same model family for both the application and the judge, because they'll grade each other's homework generously. Use a 1-4 scale rather than 1-10, because judges lose reliability at fine-grained scales. And validate the judge against human-labeled examples before you trust it in CI. If your judge doesn't agree with human raters about 80% of the time, it isn't a judge. It's noise with a score attached.
Calibrate to risk. Not every AI feature carries the same stakes. A brainstorming tool and a patient-facing healthcare assistant don't belong in the same risk tier, and they shouldn't get the same evaluation depth. For low-stakes features, a cosine similarity threshold of 0.60 and a basic judge score might be plenty. For anything where a wrong answer causes real harm, like medical, legal, or financial output, you want thresholds in the 0.85 range or higher, human review in the loop, and a panel of judge models rather than a single one.
I see gaps even in organizations that have figured out pre-production evaluation, and it's almost always the same one: they treat launch as the finish line.
AI quality degrades silently. Models are updated without announcement. Your retrieval system pulls different documents as the knowledge base changes. User behavior shifts. Any of these can cause what I call output drift, where your feature produces measurably worse responses over time with no obvious cause and no alert firing.
The teams staying ahead of this have closed the loop between production and their test suite. They sample production traffic, run it through the same evaluation infrastructure that runs in CI, flag traces that score below threshold, and have a human confirm whether those are real failures. Confirmed failures become permanent test cases.
The concept isn't new. Traditional QA closes the same loop when production bugs make it into regression suites. The difference is that in AI QA, instrumented right, the loop runs automatically and continuously, so the test suite grows from production at a pace traditional QA rarely achieves.
None of this is free or easy. LLM-as-judge evaluation costs real money, because each judgment is an API call. You have to tier your test suite deliberately: deterministic checks on every commit, similarity checks on every PR, judge evaluation on release candidates or nightly runs. Run the full stack on every developer save and you'll burn your budget before it improves your quality.
Building the human-labeled calibration set to validate your judge, the 50 to 100 labeled examples you need to confirm it agrees with human raters, also takes time. Teams that skip this step end up with automated evaluators that report high pass rates while real quality issues ship to users. I've seen it happen.
The tooling has gotten a lot better. Frameworks like DeepEval, Promptfoo, Ragas, and Langfuse handle the infrastructure so you're not building the harness from scratch. But the judgment about what to measure, which thresholds matter, and what risk tier your feature belongs in still requires a human being who knows the product.
The core skills are still testing skills: edge-case thinking, test design, and a real understanding of how users actually use the system. What's new is the evaluation layer on top, which means understanding non-determinism, designing eval sets diverse enough to catch real failures, and writing a judge rubric that holds up under scrutiny.
I don't think QA engineers need to become data scientists or ML engineers to do this well. But they do need to get comfortable with statistical thinking, with distributions rather than binary outcomes, and with at least one of the evaluation frameworks that's become standard in this space.
The patterns are established and the tools exist. What's missing in most organizations is the awareness that traditional testing isn't enough for these features, plus a clear picture of what to do instead.
That's what I've been trying to put together.






Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.


