


I've spent 25 years helping organizations build quality into their software. One lesson has come up over and over again, in hundreds of engagements across dozens of industries: The earlier you catch a problem, the cheaper it is to fix.
We call this "shift-left" in software testing circles. It's not a new idea. But it took me an embarrassingly long time to realize we'd been ignoring it completely in one of the most important places it applies: data.
Here's a conversation I've had more times than I can count. A data engineering team builds a beautiful pipeline. Modern architecture, clean code, well-documented. They're proud of it, and they should be.
Then I ask: "What tests do you have in place for the data flowing through it?". The answer, more often than not: "We have some row count checks at the ed. And we'd know pretty quickly if something broke badly." That's the quality strategy.
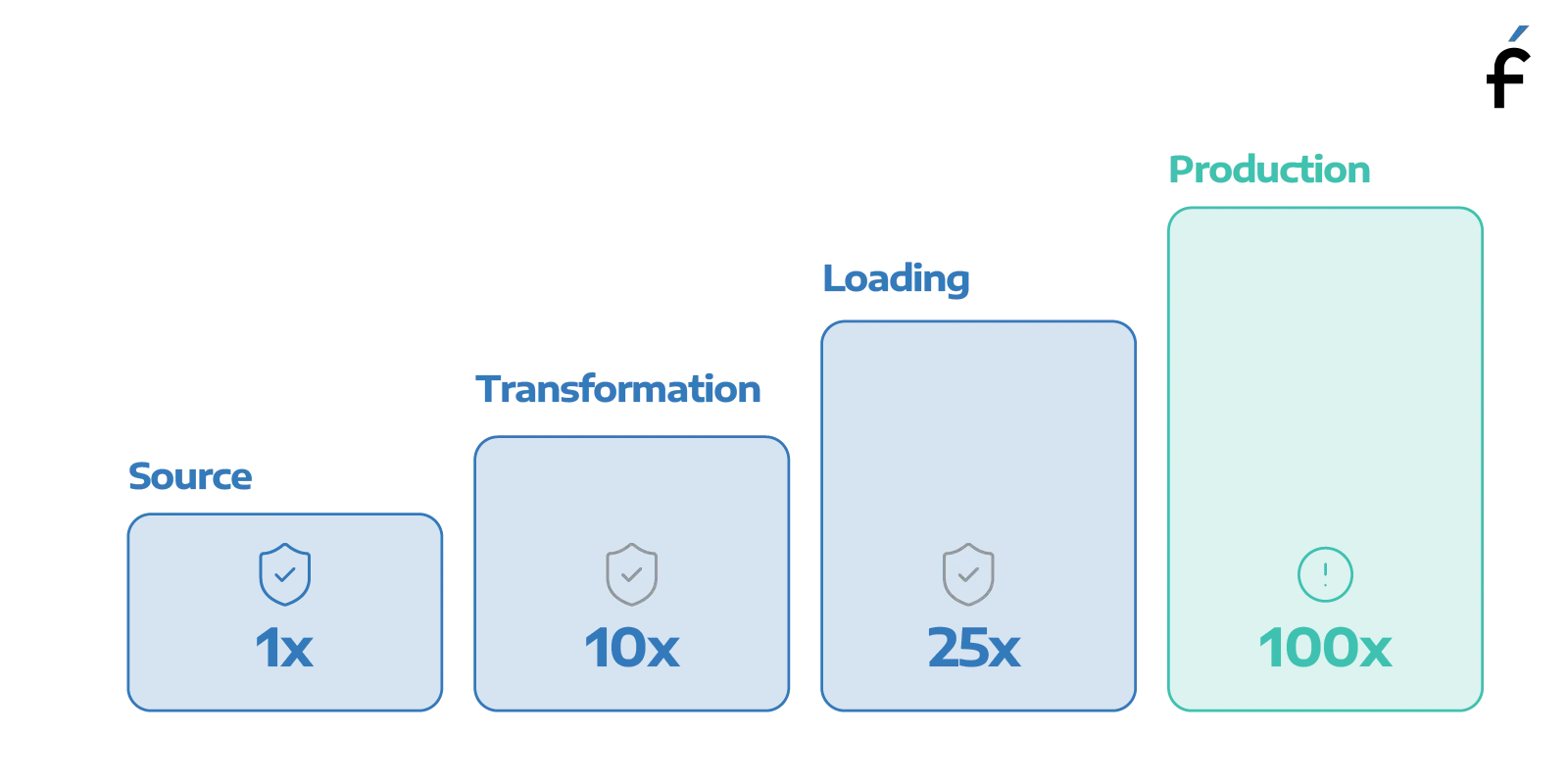
Now imagine a software engineer giving me that answer. I'd tell them that they were flying blind. Because by the time you "know something broke badly," it's already in production. Users have already hit it. Developers are already in firefighting mode. You're paying 100 times more to fix it than you would have at the source. The exact same math applies to data. We've just collectively decided it's how things work.
Most people understand preventive maintenance in theory. Change your oil every few thousand miles. Get your annual physical. Schedule the HVAC service before summer. The problem is that skipping these things never hurts immediately. You skip one oil change and the car still starts. You skip another, and another… and the engine keeps running just fine. There are no warning lights. No obvious symptoms. Everything seems okay. Until the engine seizes.
At that point, the repair bill is ten times what the oil changes would have cost over the past three years. But worse than the cost is the surprise. Nothing warned you it was coming. The car gave you every indication it was fine.
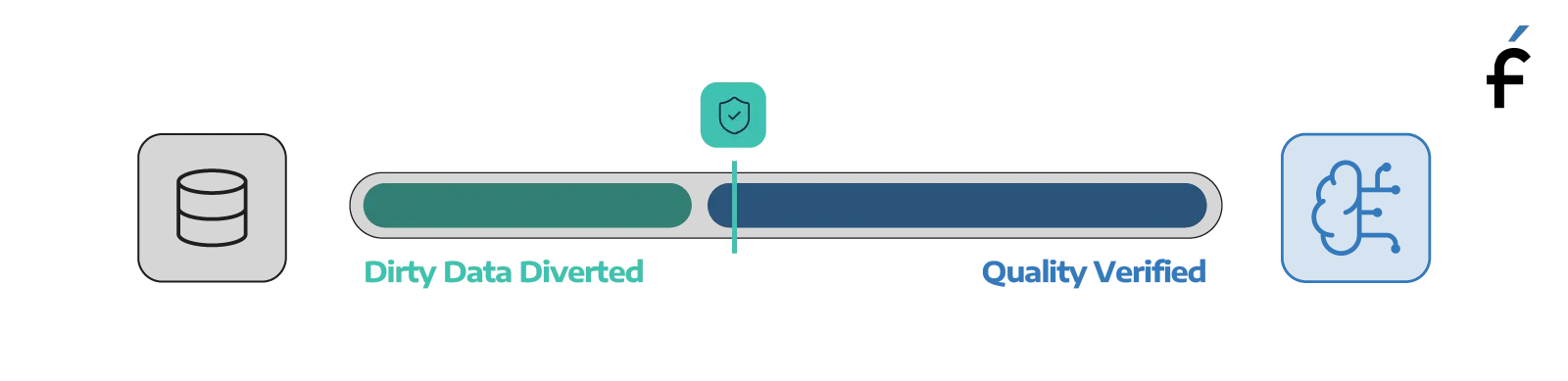
Data quality debt works exactly the same way. You skip the quality gates on your migration, and the data lands in the new environment without issue — or so it appears. You skip the pipeline tests, and the dashboards keep refreshing on schedule. You skip the training data audit, and the AI model starts producing outputs that look reasonable. Nothing sends up a flare.
Until the VP asks why Q3 revenue looks different in the new system than the old one. Until the AI initiative gets shelved because nobody can explain why the model's recommendations stopped making sense. Until someone realizes that numeric precision was silently lost during the migration six months ago, and every report since then has been wrong.
That's not a minor inconvenience you can patch over a weekend. That's an engine seizure. And just like the car, your data gave you no indication it was coming.
The difference between preventive maintenance and crisis repair isn't just cost: it's control. Preventive maintenance happens on your schedule, at a known price, with a predictable outcome. Crisis repair happens when the system decides, at maximum inconvenience, and at a cost you can't anticipate.
When I started my career, software teams had a similar blind spot. Testing happened at the end, in a dedicated QA phase. Developers threw code over the wall, testers found problems, developers fixed them, testers retested. Everyone was busy, releases were still late, and production was still full of bugs.
Then the industry shifted. Agile. DevOps. Continuous integration. Shift-left testing. The insight was simple: quality can't be added at the end of a process. It has to be built in from the beginning.
That shift took years to become mainstream. But it did. Today, any software team worth working with has automated tests running in CI/CD, catching problems before they ever reach production.
Data engineering is fifteen years behind on this curve. And the gap is getting more expensive every day.
Two things make data quality engineering urgent in a way it wasn't five years ago.

AI. Every organization is building AI applications, planning to build them, or being sold them. Every one of those applications is only as good as the data it's trained on. Gartner predicts 60% of AI projects will be abandoned by 2026 because the data isn't AI-ready. That's not an infrastructure problem. It's a quality problem. And it's almost entirely preventable.
Data modernization. Almost every mid-market and enterprise organization is in the middle of — or planning — a significant architecture change. Lakehouse migrations. Cloud consolidations. These are the right moves, but they're also the highest-risk moments in a data organization's lifecycle. The #1 reason these projects fail isn't technical complexity. It's data quality issues that went undetected until they were already in the new environment. The engine runs fine right up until it doesn't.
The most common pushback I hear: "We don't have time."
I understand. Data teams are stretched, requests outpace capacity, and adding quality checks feels like adding work. But here's the reality: you're already doing the work. You're just doing it after the fact, at emergency rates.
Every hour spent tracking down why the numbers in the new system don't match the old one is time a pre-migration reconciliation check would have saved. Every morning standup that opens with "we had a data incident overnight" is a conversation better monitoring would have surfaced before business hours. Every AI project shelved because nobody trusts the training data is a sunk cost that proper data validation could have prevented.
Preventive maintenance is never free. But it is predictable, bounded, and manageable. The alternative, as anyone who has towed a seized engine to a repair shop will tell you, is none of those things.
The ROI is real. The tools exist. The practices are proven. The only thing left is to stop treating data quality like a problem you'll get to eventually — and start treating it like the engineering discipline it is.
Lee Barnes is the Chief Quality Officer at Forte Group, where he leads the firm's Quality Engineering and Data Quality Engineering practices. He has spent 25+ years helping organizations build quality into software delivery and, increasingly, into data infrastructure. Lee speaks regularly at industry conferences including DevOpsDays, Agile+DevOps, STPCon, and StarEAST.
Interested in talking about data quality in your pipelines or an upcoming migration? Reach out to the Forte Group team.





Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



