


Most software teams say they want quality built in. Then they treat quality like the warning light that comes on after takeoff. That approach works right up until something expensive catches fire.
Pilots learn this lesson early. Before you ever touch the throttle, you run the checklist. Fuel. Flight controls. Instruments. Trim. Magnetos. You don't skip steps because you're confident, because you're behind schedule, or because it worked yesterday. The airplane doesn't care, and the laws of physics are unimpressed by optimism, deadlines, or executive pressure.
Software systems work the same way. AI-enabled systems raise the stakes.
Enterprises are racing to deploy AI copilots, assistants, and agents into operational workflows. These systems are no longer just generating content. They're triggering actions, accessing systems, influencing decisions, and interacting with production data. Meanwhile, AI governance, operational controls, and validation strategies are struggling to keep pace.
That gap is the equivalent of skipping the pre-flight checklist.
The industry keeps talking about AI productivity gains. Faster coding, faster testing, faster operations. Fine. But speed without operational discipline is just a faster way to create a larger crater.
Quality engineering is often misunderstood as gates, documentation, and process drag. At its best, it's operational readiness: the discipline of ensuring systems are observable, resilient, secure, recoverable, and predictable before the throttle goes forward.
In aviation, nobody says, "We'll figure out whether the controls work once we're airborne." But in software, teams still deploy systems without fully understanding:
How access is controlled:
Then everybody acts surprised when things get interesting at 2:00 AM.
AI-enabled systems amplify this problem because traditional assumptions about software behavior start to break down. For years, software engineering operated around a comforting principle: identical inputs should produce identical outputs.
AI systems don't behave that way. Outputs vary. Context matters. Models drift. Probabilistic behavior replaces deterministic certainty, and correctness becomes something that has to be evaluated statistically rather than absolutely.
That changes the testing problem significantly. It also changes the operational risk profile. The old "we'll monitor it and fix it later" mindset stops working very quickly.
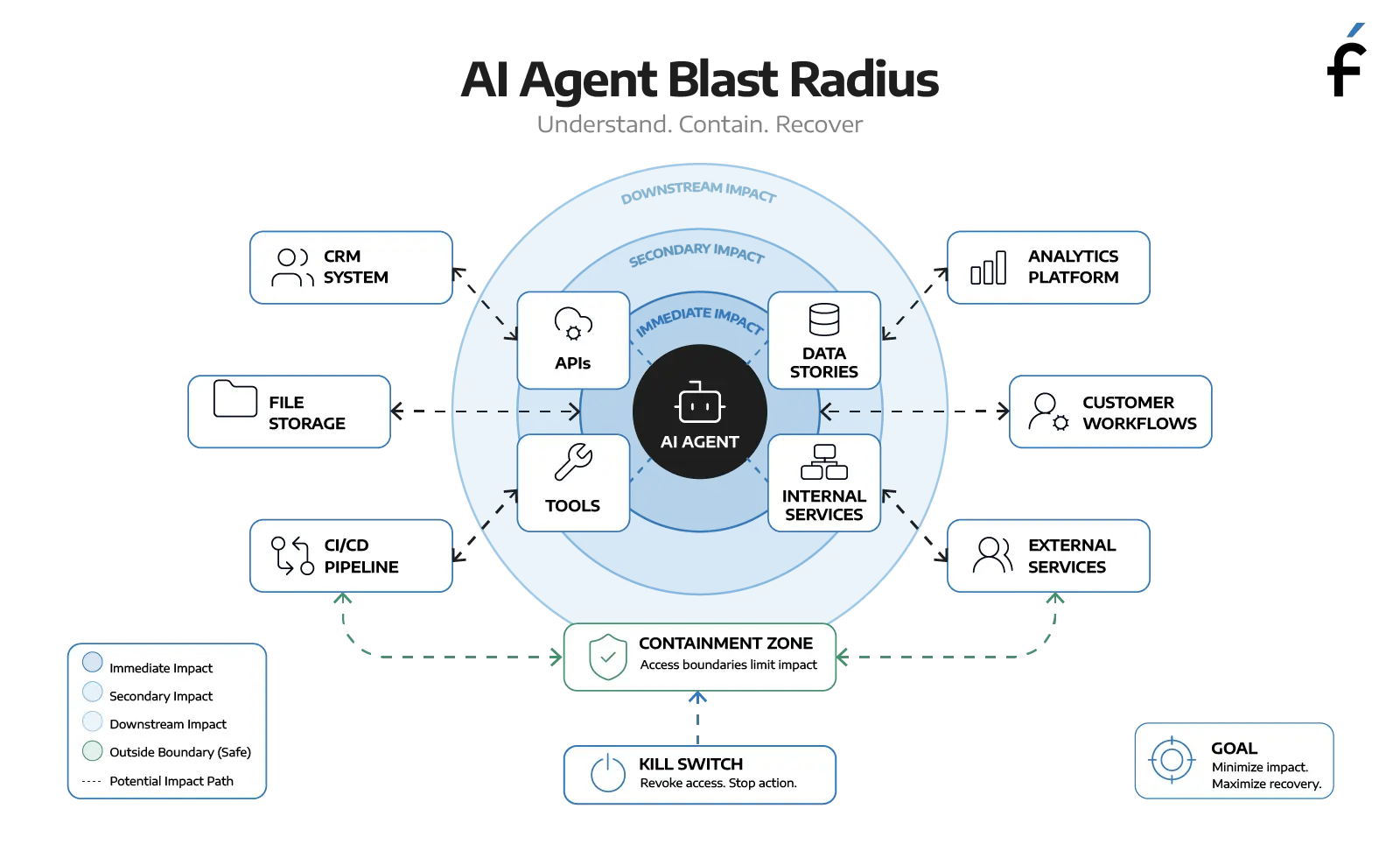
Before AI-enabled systems go into production, there should be a pre-flight checklist. Not theoretical governance slides. Not a policy document buried in SharePoint. An actual operational readiness process. Start with three non-negotiables.
AI agents and automated workflows should be treated as first-class non-human identities with isolated credentials, auditability, and lifecycle management. Not shared service accounts inherited from someone's pilot project two years ago.
If you cannot immediately answer the question, "What exactly does this system have access to?" you already have a problem.
The system should only access the data, APIs, and workflows required for its intended purpose. Least privilege does not stop mattering simply because the employee happens to be synthetic.
An AI agent with broad production access and weak constraints is essentially an autonomous chaos monkey with a business justification.
When something goes wrong, and eventually something will, containment and recovery procedures should already be tested. Not theorized. Not discussed. Tested.
Ask the hard questions:
Can you revoke access immediately?
If not, your recovery process is hope. And hope is not an engineering strategy.

A pre-flight checklist is necessary, but it isn't sufficient on its own. Leaders should be honest about what comes with it.
The tooling market is still maturing. Capabilities for AI evaluation, agent observability, and non-human identity management are moving fast but remain fragmented. Expect to assemble capability from several vendors and some internal engineering for the foreseeable future.
Organizational readiness is uneven. Quality engineering, security, SRE, and AI governance functions often report into different leaders with different incentives. Operational readiness requires these groups to share a single definition of "ready to fly," which is more of an organizational change problem than a technical one.
The skills gap is real. Traditional QA practices don't translate cleanly to probabilistic systems. Teams need to develop new muscle around AI evaluation strategies, telemetry design, and failure injection for non-deterministic behavior. That takes time and deliberate investment.
Cost is not trivial. Building observability, containment, and recovery into AI systems before deployment is more expensive than bolting it on later, until the first incident. Leaders should expect to defend that investment to finance teams who haven't yet seen the alternative.
Quality assurance can no longer be treated as a downstream testing activity. The boundaries between quality engineering, security, observability, reliability engineering, and AI governance are blurring. Modern quality engineering is increasingly about building operational confidence into systems from the beginning.
Before deploying an AI agent into production, verify the following are in place:
That is the new pre-flight checklist.
Eventually, the system is going to fly. The only question is whether the warning light gets noticed before takeoff or after. By the time the lawyer, regulator, customer, or board gets involved, it's too late to start asking whether somebody remembered to check the fuel.
Operational readiness is not a tax on speed. It's what makes speed survivable.






Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



